
Building a Scalable Inner-Source Ecosystem For Collaborative Development
A guide for organizations to set up an extensive internal software development environment, using the Julia language as example.

A scientific software developer with over a decade of experience in academia, startups and industry. My mission is to turn you into an elite numerical computing professional.
Three years ago, we decided to embrace the Julia programming language to solve the two language problem at our organization. We want our scientists to join forces with software engineers so that they can work on the same problems together. In our journey, I could have used more books or blogs to guide us on the following topics:
How to build and deploy software products with the Julia language?
How to create the seeds for an effective scientific software ecosystem?
This article is here to help you with the second topic, but I warn you that we had to figure out 1 and 2 at the same time. I intend to write more blog posts about the Julia productization aspects. Yet in the long term, I am betting on the ecosystem to radically improve our organization, so I consider that more important to blog about.
One thing I must continually emphasize is that the technology alone, regardless of how wonderful Julia is, cannot change people. What I needed was an environment where our scientists could contribute to product development in a rewarding way, while upholding the quality standards of modern software engineering. Additionally, we required a setup that could eventually scale to thousands of engineers.
An Ecosystem Blueprint
We had to figure out everything from scratch. I hope this article will help fledgling ecosystem architects to gain a head start in their organization. Consider it a guide, or a blueprint, but be mindful of the unique needs of your own organization. I will use my own experience as an example, see my JuliaCon presentation for more information.
As architects of this ecosystem, our main design choice was to have a development workflow that feels similar to being an open-source developer, to help onboard scientists and engineers with little friction. You should be able to install internal packages via a standard package manager, Pkg in the case of Julia. You can use your favorite IDE, though we advised VS Code due to the Julia plugin maturity. You work on GIT with code reviews. You have automated testing pipelines to check your commits and pull requests. Ideally, all code and tools are available to all engineers, that's what I call "inner-source". Everything should feel instantly recognizable, even if we use slightly different tools and practices than the open-source community.
Types of Repository Structures
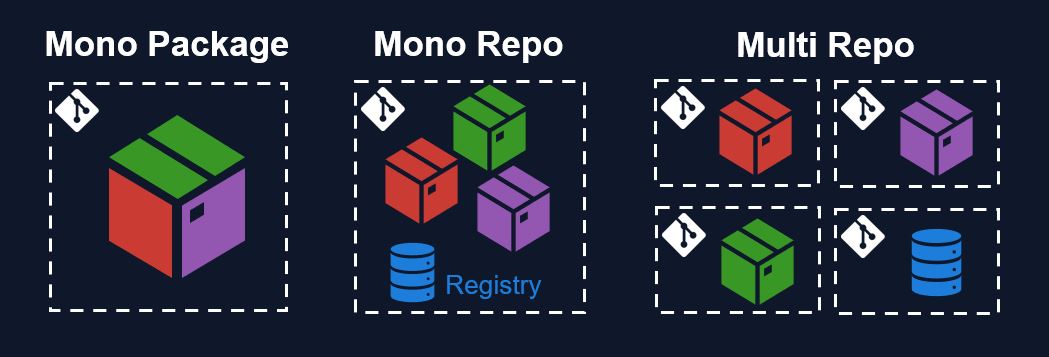
To begin, we will have to choose how we kickstart our codebases. As mentioned I wanted a full-fledged inner-source ecosystem. However, different organizations may have different desires. On a high level, I can imagine the following scenarios for your development organization:
A single repository, with a single monolithic package. Probably with internal submodules as it grows bigger.
A single repository, but with multiple packages inside. With or without a registry.
A multi-repository, multi-package setup. Similar to the public open-source ecosystem you observe on Github, including a separate registry.
What is a package registry? A registry is merely a lookup table with links to all the packages in your organization. A package manager uses this registry to find and install packages for the users, including all the package dependencies. For example, see the Julia General Registry , or the Python Package Index. I advise to setup a separate local registry in your organization for your internal packages.
A mono-repo with multiple packages seems common among startups, see this discussion here about Beacon Biosignals approach and the responses from others. But I have also heard about startups who use option 1: a mono-package setup.
The advantage of the first option, a mono-package, is that you need no serious package management. No local registry is needed to install dependencies. You clone and go. The downside is that this single package can quickly grow big and clunky, slowing down pre-compile times and maybe coupling internal interfaces. If you want to develop quickly and deploy separate modules to separate products, how will you disentangle everything? I also don't know how difficult it is to move from option 1 to option 2 once you are over-invested. Overall, I would advise option 2 to get started, if option 3 (multi-repo) seems too scary. If you immediately set up a registry and make it part of the workflow, then splitting off packages into multiple repositories should be easy in the long run.
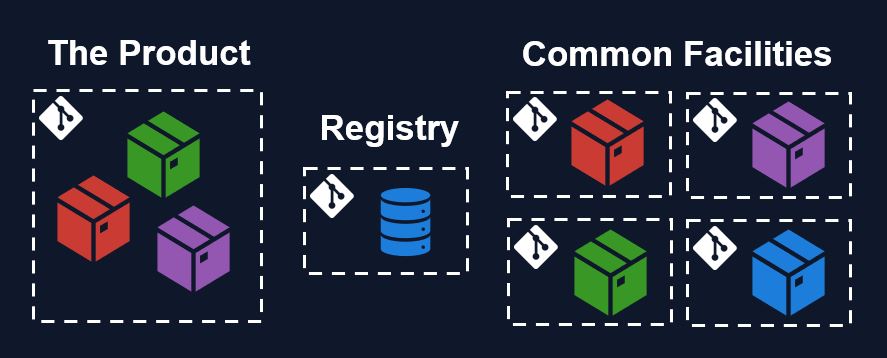
At the beginning of our journey, I immediately aimed for option 3, the multi-repository setup, because I wanted to mimic an open-source ecosystem. After a few months of working with 3 developers on our first product, we restructured the packages into a hybrid approach with one big repository with all our main product-related packages, and a bunch of satellite packages that were well-defined and reusable by future projects. The main package architecture was still rapidly evolving and the dependencies between them were not entirely clear. In the multi-repo scenario this forced us to open a lot of pull requests at once into multiple repositories for every change. To find the balance, we went with a hybrid approach. I've seen open-source projects like Makie migrate to a similar hybrid setup.
Today we still work with this approach in our department, sometimes spinning off packages out of the big repository into a separate repository whenever we think it's a common facility useful for other teams or departments. If we know at the start that a package is common, we typically immediately start it in a separate repository. Other departments sometimes follow our hybrid approach, or start with a full multi-repository setup, depending on their development needs.
Types of Packages
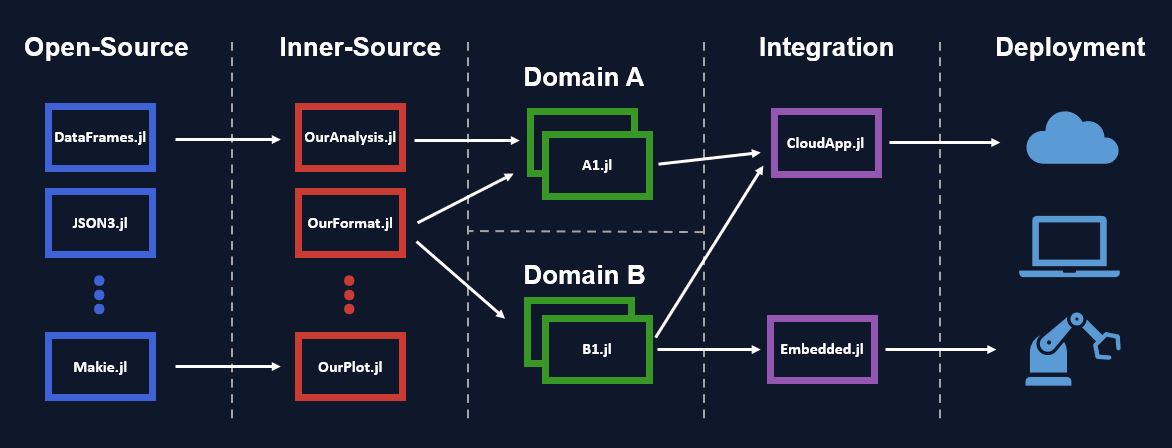
Next to setting up a repository structure in a version control system, I needed to distinguish between different types of packages, which require different ways of handling them.
Open-source packages, which may need to be checked and approved.
Inner-source packages, which are useful for multiple groups besides your own, or even common for the entire organization. These packages may depend on open-source packages.
Domain-specific or product-specific packages, that only apply to a single group in your organization, where access might be restricted to a need-to-know basis. These packages may depend on inner-source and open-source packages.
Integration packages. These are end-points from the development ecosystem perspective. For example, a Julia REST server which provides an API around a set of domain-specific packages and gets deployed into a cloud application. Or a package that gets compiled and integrated into C++. Multiple domains may collaborate and deploy together, or independently, that depends on your product environment.
I will not go into the deployment considerations in this article. But I often had to explain to managers these different types of packages and their relationship to the final product.
We are also currently considering to add some kind of tags to certain package versions, to distinguish in maturity levels or use-cases:
Prototyping packages for personal projects, or very early research explorations among a few scientists.
Research packages, used by many scientists, but not used (yet) in commercial products. Plotting and data analysis packages typically fall in this category.
Tooling packages, used for testing or deployment. Important for developers, but not shipped to production.
Production-grade packages, shipped to customers. These should not break!
We're still working on the exact details. Typically it's pretty clear which package is what, especially if a package is still version 0.x.y then it's probably a prototype or research package. But there is mobility between the package types. A research package can suddenly become integrated into a new product, at which point we need to address the quality and reliability of the code, and make it clear to the researchers how to continue working with this more mature package.
Typical Developer Workflow
As an inner-source ecosystem architect, the developers are your customers. You should design the system such that it supports an ideal developer workflow. For you developers it should feel low-effort, and rewarding, to make high quality deliveries.
We typically consider two types of profiles:
Package users that do not develop packages, such as data analysts.
Package developers that write the package code.
Often the package user and the package developer are the same person, especially at the beginning of your ecosystem when there are no packages yet. Therefore I focused most of my effort on making the life of the developer easier, hoping that the developers will make the user's life easier.
The developer workflow is not linear, but if I have to linearize it for the sake of this article, I would divide it into the following steps, all of which need software infrastructure.
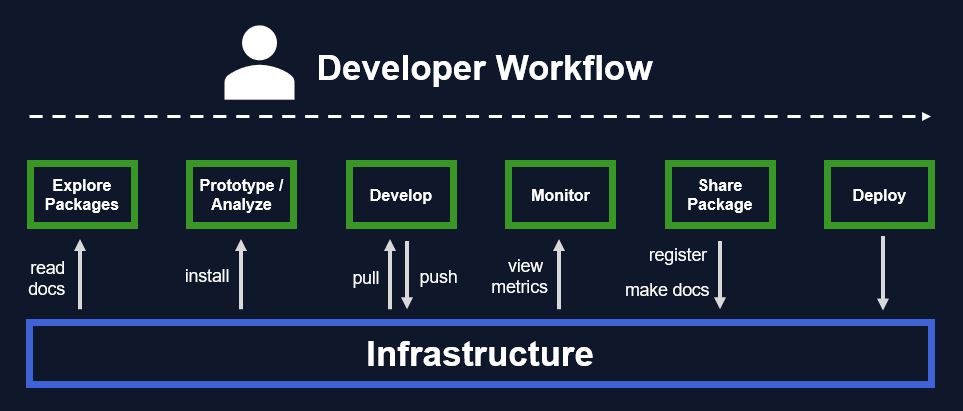
Explore Packages - Anytime you start, you'll probably have to do some exploration of existing package. To figure out if something already exists out there in the world, before inventing it yourself. You want infrastructure that makes it easy to search and discover packages. And it should be easy to read the package documentation.
Prototyping - Once you found the interesting packages, you probably want to do some prototyping or data analysis, or whatever is necessary to figure out your new requirements. In this phase you are still a passive user of the ecosystem, merely installing packages. But package installation should be easy with a registry and package manager in place. Simple Pkg.add("InternalPackage") and use it in your development environment.
Developing - Once you contribute to an existing package, or develop a new package, you'll have to use standard GIT tooling to clone the code and commit new changes. You write tests and when committing changes to a package, the continuous integration systems get triggered, automatically running all tests and other checks, similar to an open-source contribution.
Monitoring - During development, any contribution is already qualified, but as developer or package owner you want to monitor the code quality over time, with metrics such as code coverage, to make sure your packages are continuously improving. (To be fair, we enabled this step last.)
Sharing - After creating a new package version, you want to update the internal registry to share this new version with others via the package manager. You also want to create and host the updated package documentation. This step may or may not be fully automated in your organization.
Deployment - Packages that are released as formal products should be deployed, as libraries or microservices or otherwise. We automated this in the main branch of the product integration packages, once a new version is released.
Package Development Infrastructure
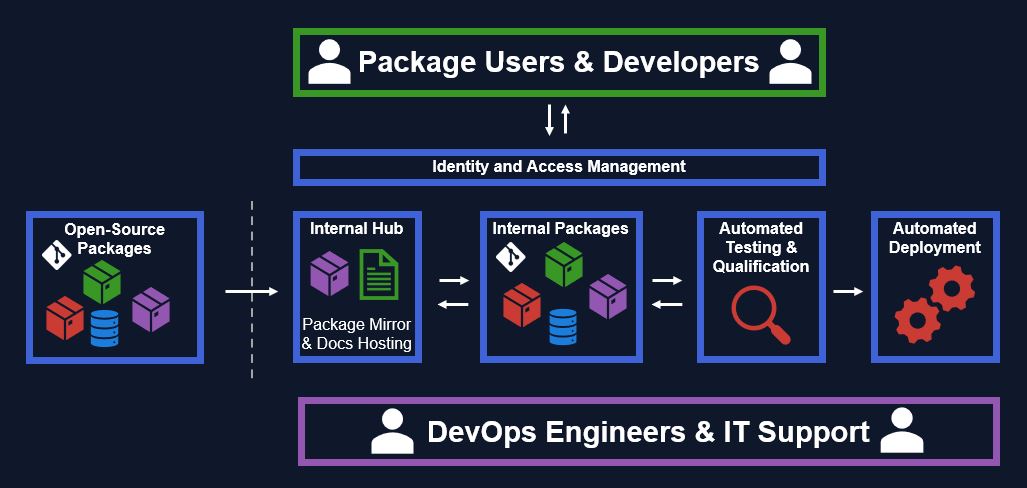
We need many tools to support a developer-friendly workflow inside a large ecosystem. We grew all this infrastructure organically over the years, solving one bottleneck at a time. Here are some of the many tools and practices we worked on, roughly in chronological order:
I assume you already have a GIT repository hosting system in place, such as Gitlab, Github or Bitbucket.
I also assume you have some Identity and Access Management (IAM) layer in place, so users can connect to the infrastructure tools with your company credentials. I'm adding this layer explicitly since access rights are often a source of bureaucracy and frustration. The "inner-source" concept can be at odds with IT security people who want to restrict all access by default.
With basic IT tools in place, the first thing I did was set up a local registry. With Julia this is easy since the registry just another repository. I did it in an afternoon and it saved us endless effort. With Python I know that it's a bit more tricky to set up a local PyPI.
Create your first packages and figure out their dependencies, together with a high level strategy for repository ownership among the different projects and groups within your organization. This is a complex topic, and the structure will evolve, but a solid start based on real domain experience helps a lot here.
The value of workshops and courses to teach multi-package development, should not be underestimated, especially for scientists with limited software experience. Be ready to endlessly explain GIT, SSH keys, test-driven development, CICD, language fundamentals, and much more.
Automated pipelines for each package are crucial. This enables scientists and developers to automate their quality checks, instead of running tests and checks manually. If this step is easy, scientists will use it for their research packages, giving them early DevOps training. This makes the later handover to software engineers more pleasant and reproducible.
Documentation hosting for each package, to explain the API and provide examples for package users. I hope the benefit of good documentation is clear to everyone. Maybe in the future an AI can automatically explain how your code works, but not today.
Production-grade build pipelines, as an extension to the existing automated testing pipelines, to integrate packages into bigger systems. Otherwise, your scientists will be spending endless time manually compiling and delivering code. Is that a good use of their time?
Qualification pipelines, where we test all registered packages at once. This was first built to qualify new Julia language versions before rolling them out, but we run it more often for ecosystem-wide testing. Maybe we'll go to a nightly run like the open-source community performs here.
IT Security assessments of our open source code usage. For example, to enforce correct license usage and guard against supply chain attacks. In general, you probably want an internal mirror server where you store all (approved) open-source packages.
Formalized coding standards and style guides. If you don't have these, a lot of time in code reviews will be wasted on silly aesthetic arguments about the best way to define a function.
... and much more
It's important to quickly build a solid foundation that supports your developers from day one and nudges them towards delivering high quality. After that you can continuously improve the workflow of your developers, adding, removing or changing tools as required.
I am very happy that we now have a serious set of development tools in place, supported by amazing DevOps and IT engineers. This took considerable time and effort to get into place, as the architect you'll need long term commitment to make this happen.
Package Architecture

A difficult topic, especially when working with many scientists with little software engineering backgrounds, is figuring out the best configuration of packages. What should you put in which package? How many packages do you need? When should you split a package? What should each package APIs look like? How can packages work seamlessly together where necessary? How should packages depend on each other?
I advise to study Domain-Driven Design (DDD). Besides that it's endless tinkering based on real-world experience of your business domain, continuously refactoring, and hoping Conway's law doesn't get in your way. Especially at the start, I was heavily involved in writing the code of many of our packages, building products while trying to avoid big bottlenecks for the long term. I am sorry to say that we have not found a shortcut for deciding on the right package architecture.
One trick that helps us to refactor safely is to define an "interface package" that your users can rely upon. Then you can refactor and restructure packages behind that interface while keeping the interface package itself backward compatible. Users do not enjoy constantly re-learning how your package works. In the previous section named "Types of Packages" I discussed the integration packages, which also serve this interface package purpose, if you consider the production systems as a user.
Deviations From Open-Source
A business has different requirements than the open-source community, which results in some deviations from the open-source setup. Here are just a few differences that I learned to be mindful of and that I had to explain to junior developers:
Rapid development. Typically the pace of development is faster in a business, with multiple developers working full-time on multiple packages at once. If you are unable to separate concerns properly, multiple teams may even be working on the same package at once, with a lot of possible chaos.
Product integration. Open-source development is all about sharing packages with users and fellow programmers. A business is all about building products and services, so there is much more emphasis on integrating with cloud applications and embedding in devices, and everything that revolves around that.
Access restrictions. Due the risk of disclosing sensitive information and other security concerns, companies will have much more strict access control. In an open-source world, everything is transparent and accessible to everyone. In your inner-source world, this may vary per package.
Conclusion
In conclusion, building an inner-source package ecosystem requires careful planning, a solid foundation, and continuous improvement to support developers in delivering high-quality software. By adopting best practices from open-source communities and adapting them to fit the unique needs of an organization, you can create a thriving ecosystem that fosters collaboration between scientists and software engineers, ultimately improving development effectiveness.
Continue Reading
How to solve the Two Language Problem? - An overview of software technologies to get speed and simplicity at once. Comparing Python, C++, Cython, Numba, Julia and more.
Automate your Code Quality in Julia - An overview of tools and methods that help improve your code.
My Target Audience - Where I explain what kind of people I have in mind while writing this blog. Includes the Two Culture Problem as I observe it.
Organizational Refactoring (on my previous blog) - About the human challenges of creating a better scientific development organization.




